
18.08.2019

Základ zadání tohoto projektu spočíval v poměrně jednoduchém úkolu - převést velké množství textových souborů do XML. Samozřejmě zde byla řada podmínek, převodů datových formátů, doplňování dalších informací. Zkrátka bylo třeba využít nejen řadu technologií, ale také vymyslet nejvhodnější postup, a to ani nemluvím o nástrahách, které se při testovacích zpracování objevily.
Aktualizace textu - viz kapitola "Aktualizace 29. 2. 2020" před závěrem článku...

Technologie
Od počátku bylo zřejmé, že převodník bude programován v Delphi a za použití řady dalších komponent a knihoven, které zajistí kvalitní profesionální výstup. Protože bylo také jasné, že převod bude docela časově náročný, bylo vhodné upravit aplikaci tak, aby zamezila vypínání/usínání počítače. A protože, jak už jsem zmínil v úvodu, šlo o docela velký objem dat, bylo třeba se zamyslet nad co nejoptimálnějším zpracováním, které zajistí rychlý průchod, nebude příliš vytěžovat paměť ani procesor, ale zároveň bude schopen veškerou aktivitu dostatečně logovat, aby bylo možné analyzovat problémy a celkové zpracování dále ladit.
Datová náročnost
Na vstupu mě čekaly téměř 2 miliony textových souborů, které obsahovaly 40 milionů článků, o celkovém objemu 278 GB. Jak bude patrné z dalšího, výsledek zabíral 122 GB a jednalo se už jen o 7109 XML souborů. Ovšem již z prvních testů bylo zřejmé, že by bylo vhodné použít nějaké metody na zrychlení celkového zpracování. A nejde jen o zpracování jako takové, ale i celkové ladění - pokud by bylo něco špatně, vše se musí spouštět znovu a znovu, a zde se každá hodina hodí, i když jde jen (většinou) o strojový čas.
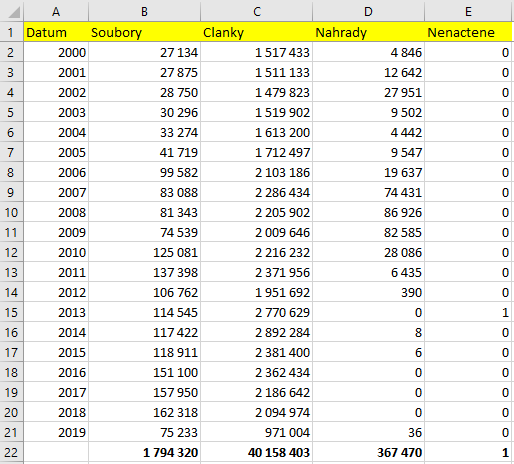
Paralelismus - ano nebo ne?
Samozřejmě jsem stál před velkým rozhodnutím, zda celý projekt pojmout paralelně nebo ne. Tím mám na mysli především to, zda mám aplikaci napsat jako paralelní, tedy nativně (z hlediska aplikace) využívající všech dostupných jader/procesorů. A pokud jste někdy psali paralelní aplikaci, tak víte, že to je poměrně složité a její ladění je téměř nemožné. Nechme stranou problémy s logováním (paralelní přístup do jednoho souboru), nemožnost logování do okna (do okna může zapisovat pouze hlavní vlákno), ale také to, že jsem potřeboval nějakým způsobem řídit, co se bude zpracovávat. Tedy ne to pustit na celou hlavní složku a jen čekat, jak to dopadne. To všechno a především vědomí toho, že se jedná o jednorázovou akci, mě vedlo k jednoduššímu, ale nakonec mnohem elegantnějšímu a pružnějšímu řešení.
Zvyšujeme výkon
Windows disponují tzv. preemptivním multitaskingem. Co to prakticky znamená? Nic extrémně složitého - vlastně jen to, že pokud máte spuštěno najednou více aplikací, tak se Windows starají o to, aby všechny aplikace postupně dostaly část procesorového času a na chvíli tak daná aplikace vykonávala, co má. Pak se procesor půjčí dalšímu procesu/aplikaci atd. Tím se de facto zajišťuje souběžné zpracování/běh všech běžících aplikací.
Takže celá myšlenka zvýšení výkonu spočívala ve velmi jednoduchém rozhodnutí - aplikaci spustit vícekrát a Windows se postarají o to, aby to běželo na více (logických) procesorech. Samozřejmě to není totéž, jako napsat multivláknovou aplikaci, ale přináší to mnohé výhody.
Přetížení procesoru a I/O operací
První pokus směřoval k tomu, že spustím aplikaci cca 20x (1 rok = 1 složka = 1 instance) a ono si to nějak poradí. Záhy jsem zjistil, že toto Windows opravdu nedávají - nejen, že nemají na mém PC k dispozici 20 procesorů/jader, ale pochopitelně docházelo k přetížení I/O operací s diskem - tolik čtení/zápisů najednou prostě nešlo zvládnout. Tedy šlo, ale spousta času byla věnována čekání na dokončení předchozí operace, takže výsledný čas a výkon nebyl vůbec dobrý.
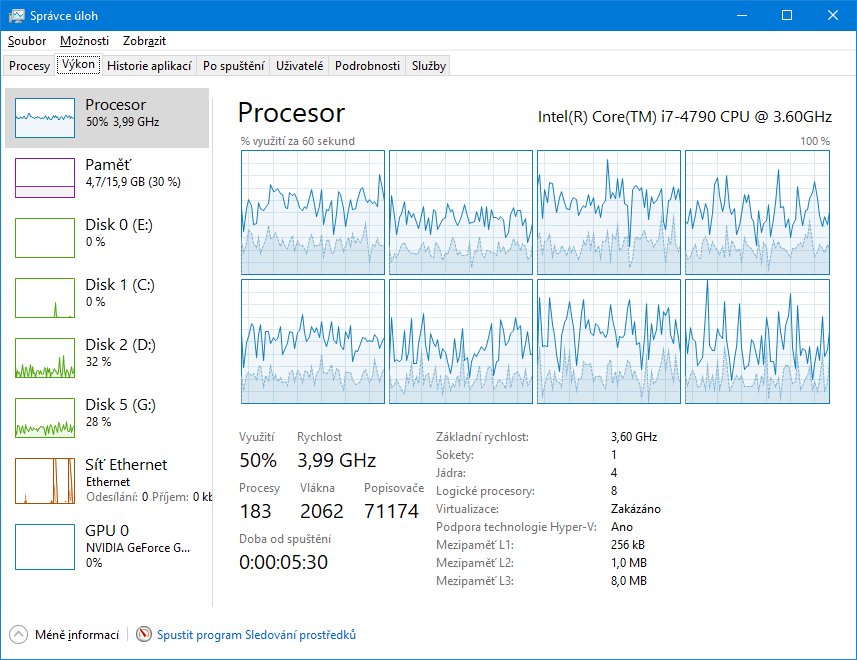
Proto jsem provedl zjednodušení. Na následujícím obrázku vidíte situaci po spuštění 4 aplikací najednou. Je to docela jasné - vytížení je na 50 %, protože počítač má 8 procesorů/jader, ale především stíhá jak disk G (zdrojový s TXT soubory), tak i cílový disk D (kam se ukládaly XML soubory). Stejně tak i 16GB paměť je v pohodě a vše se plynule a přitom paralelně stíhá.
Ovšem jak tedy "chytře" spustit paralelně 20 zpracování, aby nedocházelo k přetížení. V tom mi pomohly dávkové soubory a odhad časů.
Dávkové soubory
Rozhodl jsem se vše spustit v paralelních dávkách po 5. Tedy najednou se bude zpracovávat 5 složek. Vytížení tedy bude vyšší, než 50 %, ale vše poběží svižně a ještě bude možné případně s počítačem dále pracovat. Po spuštění 5 zpracování bude ale třeba čekat na dokončení. To se dá řešit různými způsoby, ale já jsem zvolil ten nejprimitivnější - změřil jsem si čas a další zpracování naplánoval ještě o několik minut později.
A protože s postupnými roky se zvětšoval objem dat, tak i zpracování trvalo déle. Proto v následujícím dávkovém souboru vidíte postupné čekání 20, 30 a nakonec i 40 minut. Jistě by to šlo optimalizovat, ale nebylo to nutné - úspora několika minut již nehrála roli.
Vše bylo tedy spouštěno v jednom velkém cyklu přes složky, a pouze se před některými uvedený čas čekalo. Asi si všimnete, že jsem čekal i 2 vteřiny po každém spuštění. Důvodem bylo to, aby se nevytvořil log stejného jména pro "současně" zpracovávané složky. Logovací soubor totiž obsahuje aktuální datum a čas s přesností na vteřiny.
@echo off
color 2e
rem Zdroj TXT dat
set VstupRoot=g:\Anopress\txt\cz\
rem Kam se bude generovat vystup v XML
set Vystup=e:\Projekty\Anopress\TxtToXml2019\Data\50Vystup\
rem Kam se budou ukládat logy
set Log=d:\Projekty\Anopress\TxtToXml2019\Data\70Log\
rem zpracovávám roky 2000-2019
FOR /L %%G IN (2000,1,2019) DO call :Zpracuj %%G
color 4f
echo.
title F I N I T O
echo F I N I T O
pause
goto :EOF
rem ///////////////////////////////////////////
:Zpracuj
set Rok=%1
echo Zpracovani roku %Rok%
start TxtToXml.exe /datum=%Rok% /autorun /autoclose /vstuproot=%VstupRoot% /vystup=%Vystup% /log=%Log%
Timeout /T 2 >nul
rem cekam 20 minut
if %Rok%==2004 (
echo Cekam 20 minut...
Timeout /T 1200 /NOBREAK >nul
)
rem cekam 30 minut
if %Rok%==2009 (
echo Cekam 30 minut...
Timeout /T 1800 /NOBREAK >nul
)
rem cekam 40 minut
if %Rok%==2014 (
echo Cekam 40 minut...
Timeout /T 2400 /NOBREAK >nul
)
goto :EOFLogování
Jak jsem už zmínil výše, logování díky běžnému (ne paralelnímu) zpracování nebyl problém a mohl jsem využít svoji třídu TVKLog pro logování do obyčejného textového souboru a zároveň barevné logování do RTF Mema.
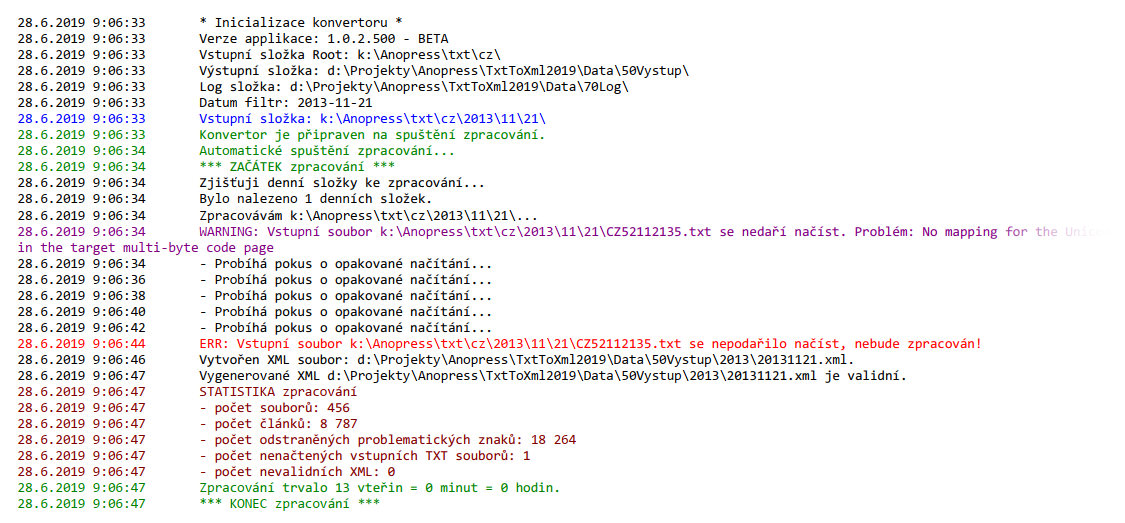
Další problémy a komplikace
Již během testů se stávalo, že se externí disk občas sám od sebe odpojoval, resp. nedařilo se načíst zdrojový soubor. Proto jsem do zpracování doplnil opakované pokusy o načítání, včetně detailního logování možného problému, resp. systémové chyby, kterou mi vrátila funkce, která soubor otevírala/načítala.
Druhým problémem bylo kódování souborů. Vše mělo být v UTF-8, ale občas se v tomto kódování soubor nepodařilo načíst. Nejprve jsem se domníval, že některé jsou v ANSI a chtěl jsem systém vybavit nějakou inteligencí, která by odhadovala kódování. Nakonec se ale ukázalo, že problematické soubory byly v UTF-8, ale nějak špatně uložené.
Aktualizace 29. 2. 2020
Po půlroce jsem na zcela novém rychlém počítači zpracovával v podstatě stejná data. Co bylo jinak a proč vlastně vznikla tato kapitola.
- Na novém počítači byl nějak agresivní Microsoftí antivirus a kontroloval i generované 50-70 MB velké XML soubory, což dost vytěžovalo procesor, ale nakonec se vyplatilo. V textech dvou článků byl i škodlivý JavaScript - autor článku o virech do něj bohužel zařadil i kód "DoS:JS/Dframe.gen"
- Musel jsem doprogramovat kontrolu na volné místo na disku, jinak docházelo v aplikaci k nesmyslné chybě - že není XML validní. Pochopitelně, když se XML neuložilo celé :-)
- Novinkou zpracování je ZIPování XML souborů a odstraňování zdrojových dat, což též výrazně vylepšilo problém z nedostatkem místa, protože v případě těchto XML souborů jde o 3-4násobné zmenšení prostoru. Zdrojových 250 GB se vešlo do cílových 60 GB.
- Pokud máte opravdu 8 jader, nikoliv jen 4 (=8 virtuálních), může být zpracování o cca 30 % rychlejší, ale pochopitelně záleží i na diskových operacích
Pokud používáte 7Zip, pak zipování s odstraňováním zdrojů může vypadat třeba takto:
rem ///////////////////////////////////////////
:Zazipuj
set Rok=%1
echo Zipovani roku %Rok%
set SlozkaXmlRocniData=%Vystup%%Rok%
set ZipSoubor=%ZipSlozka%%Rok%.zip
del %ZipSoubor%
cd %SlozkaXmlRocniData%
rem -sdel : po přidání smazat zdroj
"c:\Program Files\7-Zip\7z.exe" a -sdel %ZipSoubor% *.xml
goto :EOFZávěr
Jak vidíte, zpracování velkého množství dat vždy vyžaduje individuální přístup, zhodnocení možností, technologií, výkonu počítače, ale také výhody či nevýhody daného řešení z hlediska uživatele, který zpracování spouští.
Z prvotního odhadu postupného zpracování (12+ hodin) jsem se dostal díky řadě optimalizací a možná trochu netradičnímu přístupu na cca 2 hodiny. Ano, zabralo to relativně hodně času, výzkumu a testování, ale nalezené řešení je znovupoužitelné pro další podobné projekty a hlavně mi umožnilo zase nový pohled na problematiku hromadného zpracování dat.
